CockroachDB’s Geo-partitioning allows you to partition data using location information like country codes. If you’re wanting to partition your data by-country, your data structure will likely already have the necessary components to do so. For example, the following table lends itself to being partitioned on its “country” column, meaning rows containing a country code of ‘DE’, ‘FR’, and ‘UK’ can be pinned to European data centres, while rows containing a country column of ‘US’ can be pinned to North American data centres etc:
CREATE TABLE "person" (
id UUID NOT NULL DEFAULT uuid_v4()::UUID,
country VARCHAR(2) NOT NULL,
name STRING NOT NULL,
CONSTRAINT "primary" PRIMARY KEY (country ASC, id ASC)
);
No column?
The data we have available to use might not always be in a structure that allows for straightforward partitioning. Suppose that instead of a top-level column, our country information was buried in a semi-structured JSON blob as follows:
{
"data": {
"country": "DE",
"name": "Alice"
}
}
Happily, CockroachDB allows you to include computed columns in your primary keys, meaning we can lift the “country” field out of our JSON structure and partition with that!
To spin up an example database to work with, I’ll be making use of v19.2.0’s updates to the demo command, which allow it to spin up an in-memory, multi-node, geo-partitioned cluster 🎉. The following command spins up an empty 6-node multi-region cluster, with 3 nodes on the east coast and 3 nodes in west Europe:
cockroach demo \
--empty \
--nodes 6 \
--demo-locality=region=us-east1,az=1:region=us-east1,az=2:region=us-east1,az=3:region=europe-west1,az=1:region=europe-west1,az=2:region=europe-west1,az=3
The demo command spins up an enterprise cluster, meaning we can view the cluster in “node map” view to get a sense of where data is being stored:
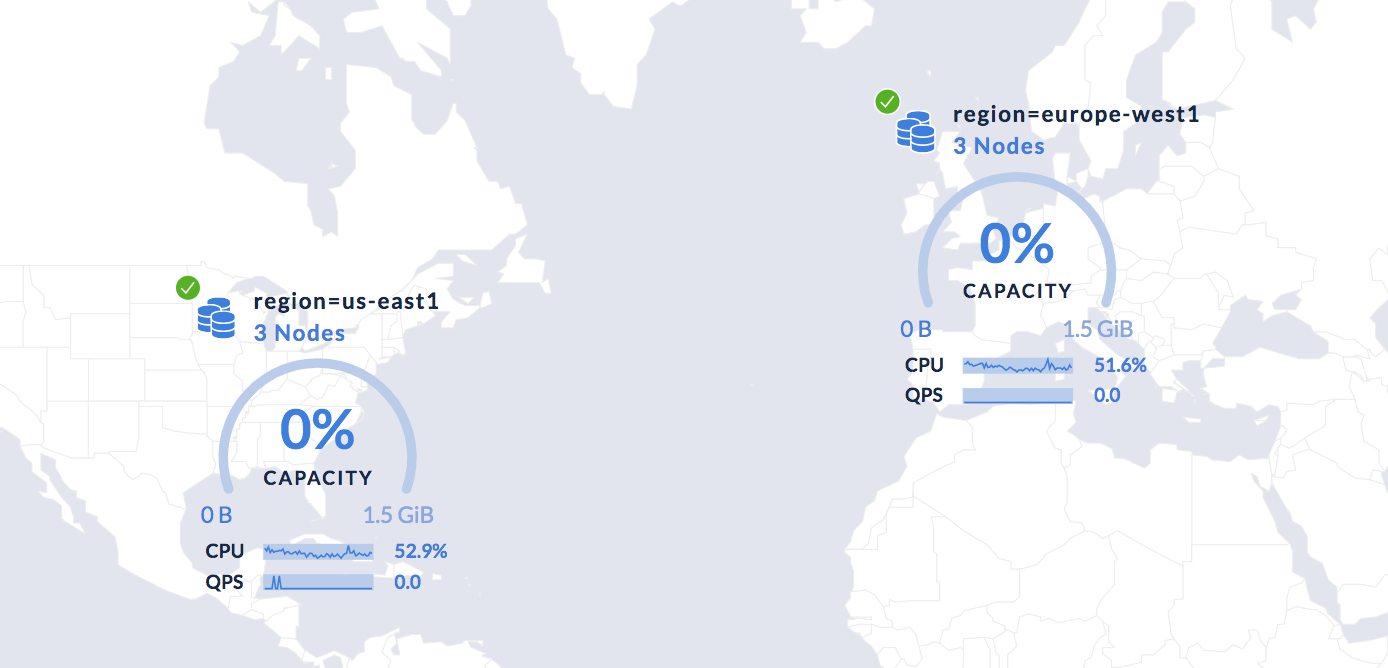
No problem!
This time in our CREATE statement, we include a column that takes the country field out of the JSON data and creates a computed column from it:
CREATE TABLE "person" (
id UUID NOT NULL DEFAULT uuid_v4()::UUID,
data JSONB NOT NULL,
country VARCHAR(2) AS ((data->'data'->>'country')::STRING) STORED,
CONSTRAINT "primary" PRIMARY KEY (country ASC, id ASC)
);
What we’re asking CockroachDB to do, is look for “data.country” in the JSON blob, lift it out as a string, create a standard column from it, and include that in the primary key. Our table from a partitioning perspective, is now equivalent to the first example.
To know we’ve successfully partitioned our table, let’s insert some rows to observe where they’re being stored once the partitions have taken effect:
INSERT INTO "person" (data) VALUES
('{"data": {"country": "DE", "name": "Alice"}}'),
('{"data": {"country": "FR", "name": "Bob"}}'),
('{"data": {"country": "UK", "name": "Carol"}}'),
('{"data": {"country": "US", "name": "Eve"}}');
Configure a partition to split the data into 2 regions, one for the US and one for Europe.
ALTER TABLE "person" PARTITION BY LIST ("country") (
PARTITION us VALUES IN ('US'),
PARTITION eu VALUES IN ('DE', 'FR', 'UK')
);
ALTER PARTITION us OF TABLE "person" CONFIGURE ZONE USING constraints = '[+region=us-east1]';
ALTER PARTITION eu OF TABLE "person" CONFIGURE ZONE USING constraints = '[+region=europe-west1]';
Use the following to view how data is being replicated. It’ll show that your US data is being pinned to your us-east1 region, while your DE, FR, and UK is being pinned to your europe-west1 region:
SELECT start_key, replicas, replica_localities FROM [SHOW RANGES FROM TABLE person] WHERE end_key LIKE '%/PrefixEnd';
| start_key | replicas | replica_localities |
|---|---|---|
| /“US” | {1,2,3} | {“region=us-east1,az=1”,“region=us-east1,az=2”,“region=us-east1,az=3”} |
| /“FR” | {4,5,6} | {“region=europe-west1,az=1”,“region=europe-west1,az=2”,“region=europe-west1,az=3”} |
| /“UK” | {4,5,6} | {“region=europe-west1,az=1”,“region=europe-west1,az=2”,“region=europe-west1,az=3”} |
| /“DE” | {4,5,6} | {“region=europe-west1,az=1”,“region=europe-west1,az=2”,“region=europe-west1,az=3”} |
US data is pinned to region us-east1 (replicas 1, 2, 3), while DE, FR, and UK data is pinned to europe-west1 (replicas 4, 5, 6).
Note that this example assumes that the person table does not yet exist. If it were to exist, you wouldn’t be able to update the table’s primary key to include information from the JSON data without first creating a new table (with an updated primary key) and copying over the data as described here.